Grids
Grids are useful for displaying large amounts of tabular data and make it easy to fetch, sort and filter large amounts of data. In fact, many of the components and features in Dime.Scheduler are implemented with data grids. As such, they have a very similar look and feel, which is why the common functions will be covered in this document.
Overview
In essence, a data grid is just an interactive table. Data in a structured format is displayed in a series of columns and rows, where a row represents a single record and a column represents a single property of that record. Because of the shape of the data and the way the data is visualized, a few features emerge to interact with the data.
Like most other things in Dime.Scheduler, users can configure many things in the grids, like which columns to display in what order and which sorting, filtering or grouping to apply. The starting point for all of these features is the column menu. Every column in any grid has access to this grid. Just navigate to a column header in the grid and click on the arrow that appears:

The menu options (and their subsequent behavior) are rather self-explanatory, but here's an overview anyway:
- You can sort on a column by selecting "Sort Ascending/Sort Descending" or cancel sorting by selecting "Clear Sorting". You can also click on a column header directly to sort on that column.
- To select the columns to show in the grid, click on "Columns" and mark or unmark in the fields list.
- You can group the data in the grid by selecting "Group by this field".
- You can toggle the grouping by (un)checking "Show in Groups"
- You can filter on a field by selecting "Filters" and typing (or selecting) the filter value in the provided area.
In the following sections, these three features will be covered in greater detail.
Column selection
Adding and removing columns
Adding or removing a column from the grid is a trivial task. Navigate to a random column's header and click on the icon, which will open the column menu. To add or remove columns, hover over the "Columns" sub menu, which will show all the available columns for that particular component.

Every grid will have its own set of columns that are relevant for that component. The columns that are already visible in the grid are marked as such in the check box next to it:

To remove a column, simply uncheck the checkbox next to it. To add a column, tick the checkbox. You can have as many or as few columns as you want.
Note: Adding and removing columns does not involve any server-side interaction. In other words, the data is already loaded for all the columns of the rows.
Change the order of columns
Changing the order of the columns is done through drag and drop of the column headers.

The green arrows indicate the location where the column will be dropped. This drag and drop feature is useful to place the columns in a sequence that makes sense to the user.
Sorting
Sorting does not need much explanation other than the fact that sorting is applied on the entire data set rather than the page in which the user is currently working in. Depending on the grid (and whether or not if the grid is paged), sorting may involve the application to hit the database to fetch the correct set.
It is worth mentioning that the column's underlying data type will have an impact on the sorting algorithm's results. It may surprise the user that "100" comes before "20" when a text field is (mis)used to represent numerical data.
How to apply sorting
Sorting can be applied in two ways: via the column menu or by clicking on the column header.
When clicked on the column menu, the user has the option to sort the column in ascending or descending order.

When sorting is applied, the column is marked with an icon to indicate the sorting order:

When no sorting is applied and the user clicks on the column header, the column will be sorted in ascending order. Afterwards, the order will be toggled to the opposite direction. There is currently no way to clear the sorting via the column header. The only is to use the "Clear sorting" menu option in the column's header menu.
Multiple sorting
It is possible to have more than one sorter in a grid. The order in which the sorters are defined will determine the overall result. For example, when the user sorts by "Job No" and then by "Task No", the data set will first sort the list by "Job No". When the algorithm has finished, it will do a second sorting run - on the sorted list - but this time it will sort by "Task No".
An example should make this clear. Here is the list of open tasks as they appear in the database:
| Job No | Task No |
|---|---|
| Job 1 | Task 5 |
| Job 2 | Task 4 |
| Job 1 | Task 3 |
| Job 3 | Task 2 |
| Job 1 | Task 1 |
When a user wants to see the jobs in descending order, this will be the result:
| Job No (DESC) | Task No |
|---|---|
| Job 3 | Task 2 |
| Job 2 | Task 4 |
| Job 1 | Task 5 |
| Job 1 | Task 3 |
| Job 1 | Task 1 |
If the user also wants to see the tasks in ascending order, this will be result
| Job No (DESC) | Task No (ASC) |
|---|---|
| Job 3 | Task 2 |
| Job 2 | Task 4 |
| Job 1 | Task 1 |
| Job 1 | Task 3 |
| Job 1 | Task 5 |
As you can see, the jobs are still in descending order, but the tasks for the same jobs are in ascending order. Depending on the type of the grid, data may be queried locally. When a local data store is used, this operation will not trigger any server-side interactions. However, when a remote data store is used (which is the case for all paged grids) the database is queried to fetch the requested page with the right set of parameters (i.e. filters, groups, sorters).
Clear sorting
Removing a sorter from a column is as simple as clicking a button in the column's header menu:

This action will cause the application to re-evaluate the query and may return a different data set.
Filtering
Depending on the underlying column's data type, a different filter type will be shown. Just like the sorting, multiple filters can be defined on the grid. Only the records that match all the filters will be returned to the grid.
There are four basic data types:
- Text
- Date
- Boolean
- Number
Text field
If the column represents a text field, the user will be able to enter a text query:

Dime.Scheduler will then retrieve all records where this column contains this text. To require an exact match, tick the checkbox below the text field 1. In addition, there are a number of symbols which have a special function:
| Symbol | Description | Example |
|---|---|---|
<> | The "not" operator that inverses the query | <>SO0006 will retrieve all items that do not contain the text SO0006 |
| | | The "or" operator | SO0006|SO0005 will retrieve all items that contain the text SO0005 or SO0006 |
| & | The "and" operator | SO0006&SO0005 will retrieve all items that contain the text SO0005 and SO0006 |
| * | The starts with or ends with operator |
|
| '' | Two single quotes - without a whitespace - implies an empty values filter. | '' |
As the examples have already shown, the special keys can be used together; a query like <>SO0006&SO|SF&<>SL* is a valid one. When we decode this string, it will place the following filters on the query:
- Exclude every record that contains SO0006;
- Include all records that contain SO or SF;
- And exclude any record that starts with SL
Date field
Date fields are slightly more complex to query, which is why the filters allow to find records with a date earlier or later than the requested date:

In this list, you will also find two special filter types: Today and Tomorrow. They're quite self-explanatory but the important thing to know is that these particular filters are dynamic while the others are static. This speaks for itself since today and tomorrow are different every day.
Number field
Just like the date filter, number filters allow you to filter on values smaller and greater than the requested number:

Boolean field
Boolean fields are usually presented by check boxes in the grids. In the filter menu, this true/false data type is visualized with "Yes" and "No" options:

Grouping
The grouping feature is the misfit among the other features, because grouping is always done locally, and not on the database level. In other words, Dime.Scheduler will only show the data of the current page in groups. This implies that it is possible that items from the same group will be spread over multiple pages, depending on the size of the data, sorting and filters. Unlike the other features, grouping is limited to just one level. Nested grouping is a feature that is not (yet) supported.
To group a column, open the column's menu and select the grouping item:

When grouping is done, it is possible to expand and collapse columns:

As the tooltip indicates, it is possible to collapse the other groups by using the CTRL + click combination.
To remove grouping, open the column's menu once again and select the corresponding item:

Paging
To handle vast amounts of data, Dime.Scheduler applies paging to the grids. Instead of showing everything at once (which would take a very long time), the grid only shows a subset and allows you to flip through the pages.

- Navigate to the first page
- Navigate to the previous page
- Current page number: you can type a page number to flip to that page
- Navigate to the next page
- Navigate to the last page
- Refresh the current page
- Number of records per page: you can use the arrows (or enter a number) to change the page size. The grid automatically reloads when this value is changed.
- Shows which set of records is shown of the total list of records in the grid 2.
Stateful grids
Some grids are stateful, which means users are able to save templates and share them with their coworkers. Every grid has a different implementation (whose buttons and flags may be included in the state), but all of them will at least store the following information:
- Selection and order of the columns
- Column width
- Column filters
- Column sorting
- Page size
It's easy to identify when a grid is stateful. When these icons appear on the toolbar, then you know it is stateful. Let's go over these buttons in the order of appearance.
For more information about layouts, read this.
Open layout
As you will recall, each dock panel contains one component. If that component is a type of grid, then it possible to apply a layout. Users may open as many layouts as they want during a session. By clicking on the lens icon, a grid in a modal window will show all the available layouts for that particular component:

An available layout is one that meets at least one of the following requirements:
- The layout was created by that user
- The layout was shared with all users of the organization
- The layout was shared with a group that the user is a member of
A key take away is that opening a layout does not modify the active user profile. Even if there is a default layout for that component in the profile, no changes will be made to the profile. This functionality allows the user to try out different presets on the fly without necessarily having to commit to those settings. State is merely a tool to store presets, eliminating the cumbersome activity of configuring grids every time you start the application.
Reset layout
Once a layout is loaded and applied, the user can continue to adjust the component's layout. This can be done for many reasons, but usually it boils down to on the fly queries to look for a certain record in the grid. Such a query may lead to a new layout (see save layout and save as layout). In other scenarios, the reset layout button can be used to return back to the original state with of the component with its own filters, sorters, groupers, etc.
Save layout
Given the appropriate security clearance, users can create and update layouts. Using the floppy disk icon, users can update the active layout. There are a few caveats though:
- Users can only update their own layouts but they can use other users' layouts for creating their own layouts.
- When the standard layout is configured and then stored, the user will be redirected to the functionality which is implemented in the "Save as" feature. This makes sense given the absence of a record in the database.
- Users can only save default layouts in profiles that they own.
- Users can not save layouts on a standard profile, a profile needs to exist before layouts can be saved.
It is important to stress that the active layout will be modified, not necessarily the default layout. When you start Dime.Scheduler with a default profile which has components with a default layout, then the active layout is equal to the default layout. However, when you open a different layout, then this item becomes the active layout. Saving the changes will be applied on that particular layout, not the one before (or the default layout, for that matter).
Save as layout
The save as feature has the same intuition as text processors such as Microsoft Word. Instead of overwriting the document, you create a new document when you use the "Save As" feature. The save as layout works just like that. To save the new layout, Dime.Scheduler needs information such as the name, whether this needs to be the new default layout and the sharing options. All of these questions are prompted in the modal window:

Manage layouts
The last feature of managing state is the one that allows you to change the layout's name, mark it as the default layout for that component and to delete it altogether.
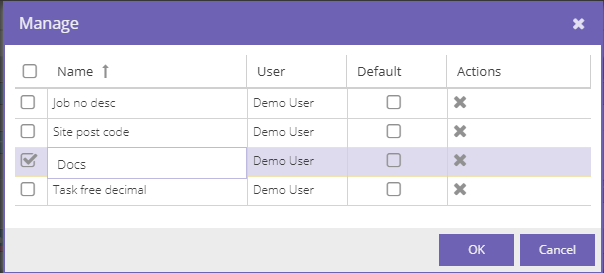
Every component in the profile is eligible to have its own default layout. For example, two open tasks grids in a profile may have different default layouts. This is also the reason why a profile needs to be present in order to store layouts.
The same caveats as in the save layout apply: users can only remove their own layouts and set their own default layouts for the profiles.
Optional feature: Search
Many grids in Dime.Scheduler also have a search bar. It uses the framework that can be found in the column filters but has a slightly different approach. The main difference is that the search bar does not filter on one specific column, but on all visible columns. Because of this, the filter is much wider in scope than a column filter.
Suppose the following open task grid configuration:
| Job No | Task No | Customer Name |
|---|---|---|
| Job 1 | Task 1 | Customer 1 |
| Job for Customer 1 | Task 2 | Customer 2 |
| Job 3 | Task 3 | Customer 3 |
When the user wants to search for "Customer 1", Dime.Scheduler will look in the "Job No", "Task No" and "Customer Name" columns for a value that contains "Customer 1". When looking at the data, there are two rows in the specified columns that do.
In contrast, if the user would have applied two column filters on "Job No" and "Customer Name", there would have been no matching data because no record has both "Customer 1" in the "Job No" and "Customer Name" fields. This is the type of question that the search bar can handle, which defines a query as "any match in any of these columns will do".
Export
The icon enables you to export data to Excel files. Like the state functionality, the visible columns (and their respective ordering) will be exported to the requested file format.
When this button is clicked, the file will be downloaded right away. The file name format is defined as follows: Dime.Scheduler [Grid type] [User Name] [Date].xlsx.
It should come as no surprise that this is what you can expect inside the file:
Copy data
Data in the grids can be copied by using traditional text selection techniques; simply select a cell and start dragging until the text you want to copy is highlighted.

Then it is simply a matter of entering the CTRL + C keyboard combination to copy the data to the clipboard. It is possible to copy multiple rows and columns. Depending on where you will paste the data, the software will be able to use the same tabular format.
Some grids have additional drag and drop capabilities. It is hard to tell when a user is dragging a record or when text is being selected. In order to prevent unpredictable situations, an extra button is added to these grids to toggle the drag behavior. For these grids, the default behavior is drag and drop. Text selection mode can be enabled by clicking this button, thereby temporarily disabling the drag and drop. Clicking the button once more will restore the original setting.